



AI Alignment With Almost No Jargon
Dumbing it down is how I learn! 📎


These past few weeks I took an AI alignment course. Am still taking it, in fact, but the learning part of it is over. Now starts the project phase, in which I am supposed to complete a small project. In my old personal tradition of feeling inadequate at coming up with research questions, I don’t know what to do yet and am already late at deciding this, but whatever. I’ll come up with something.
Because I need to be thinking about AI alignment this week, it seems worth writing a summary post on the topic. For some reason I’ve always been somewhat confused by what alignment actually is, beyond “making sure AI models are aligned with what humans want,” and the course was helpful in clarifying that. Hopefully I can communicate some of this enlightenment. I’ll give myself two constraints, though. First, be unserious. Alignment is often way too serious! Second, not use any single word more specialized than “alignment” and “model,” except in italics to let readers know what the usual terms are.
I do need model, though I kind of hate this extremely vague word, because I need a way to refer to AI systems. That’s all a model is, in this context. A complicated mathematical object that has “learned” something and is therefore able to “model” a part of the world, for example OpenAI’s GPT-4, which has learned all the text on the internet and is now able to model, i.e. guess, how to complete text given to it.
So, how do we make sure GPT-4 and its cousins are aligned with what we want?

I. AI alignment within AI safety
The first thing to realize is that alignment is not the same as AI safety, but is a part of it. AI safety is the field of making sure AI doesn’t cause harm, including various subfields such as making sure an AI system doesn’t make dumb mistakes (competence), making sure the laws around AI are well-written (governance), and making sure we know what it even means to cause harm (the age-old field of moral philosophy). Alignment is the part that is concerned with ensuring that an AI model does what the people who made the model want it to do, under the (hopefully true) assumption that AI makers don’t want to cause harm.
(In theory, a supervillain who deliberately wanted to use AI to turn the world into paperclips might also have to deal with the alignment problem, i.e. how to make sure the AI actually does that. One hopes that no such AI supervillain arises, although there sure are some worrying signs).
It’s common to further divide alignment into two kinds:
Succeeding at telling the AI what we actually want (i,.e. the goals) in a way the AI can understand.
Succeeding at getting the AI to follow (its understanding of) the goals.
The first kind is called outer and the second inner and these terms are so confusing I suggest you forget this sentence right when you’re done reading it.
An example of misalignment of the first kind is anything that can be described by Goodhart’s law,
Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.
Sorry, that contains jargon, but I couldn’t resist pointing out that the original version of Goodhart’s law was meant for the monetary policy of the United Kingdom in 1975. You may know it better in its more general formulation:
When a measure becomes a target, it ceases to be a good measure.
If you care about happiness and your way to measure that is how much people smile, your AI could learn to make people smile without making them happy, for example by threatening them with a gun. This is a terrible example but you get the idea.
The second kind of misalignment occurs when we manage to communicate the actual goal, and the AI seems to actually learn to a way to accomplish this goal — except that it learns a solution that doesn’t actually work in the real world.
You somehow manage to teach the model what happiness is, and your AI actually makes people happy when you try it on your test environment consisting of educated professionals in North America — and then you deploy it in South Sudan or something and the solutions for happiness it knows don’t work there because of cultural reasons. Sorry, that’s another terrible example. I should disclose that I am half-drunk at a bar writing this.

II. Okay so what if we just make a really big effort to tell the AI what we want?
The most famous method to align an AI model is called (warning: jargon incoming) reinforcement learning from human feedback, RLHF. Let’s just ignore the reinforcement learning part for now and call this human feedback.
You have an AI chat model, already trained e.g. from all the text on the internet. Obviously it has learned a lot of crappy and harmful stuff from this. How do we get it to give nice, pleasant chat responses even though it has seen Man-Made Horrors Beyond Our Comprehension? You hire a team of humans — who can be expected to have values aligned with other humans — and you ask them to rank responses made by the model (including some that are AI-Made Horrors Beyond Our Comprehension). Then you create a new copy of the model and give it this feedback, with the goal of updating some of its billions of mathematical components according to what good responses consist of (this is the “reinforcement learning” part). The result is an updated model that has learned the proper way to behave when asked questions. More nice and pleasant answers, fewer AI-Made Horrors etc.
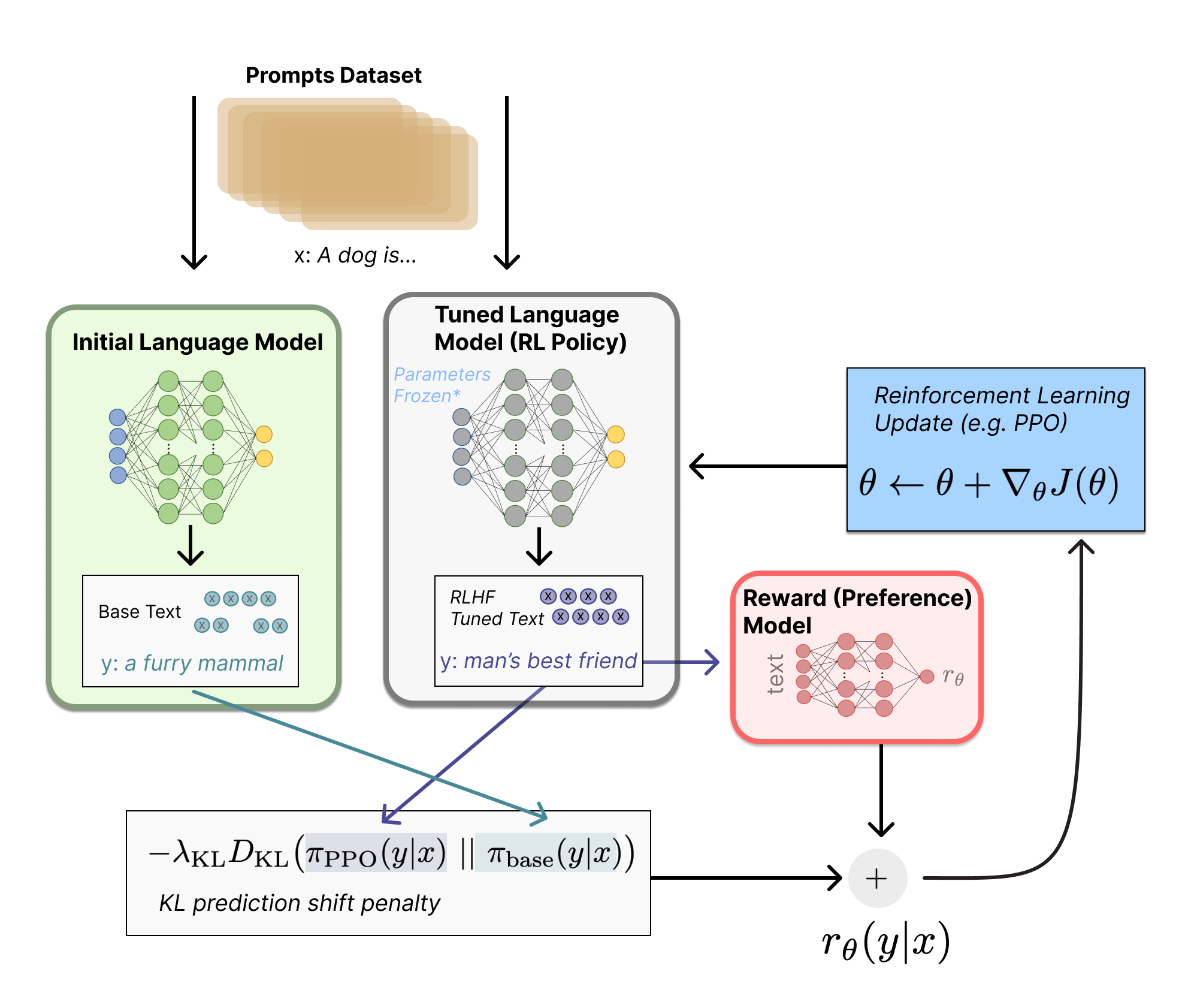
This works pretty well in practice, well enough that GPT-4 and its cousins were released to the general public. It does, however, come with some pretty fundamental limitations.
For one things, are humans that great at giving feedback? Probably not! Humans are biased, and lazy, and sometimes they’re just bad people who give incorrect feedback just for the lolz. These issues can be mitigated with the right incentives to good behavior (for instance, you’ll get more money if you do a good job), but that still leaves problems such as the fact that humans can’t evaluate difficult tasks. If you had to rank two complicated mathematical proofs created by an AI meant to do complicated math, how would you do?
More generally, human feedback is only an imperfect representation of what values the designers of an AI may want to instil into it. It can help mitigate the risks of misalignment, but it can’t solve the problem on its own. In theory it could even worsen it.

III. A constitution by the people, for the people AI
Meanwhile, the good folks at Anthropic, my favorite competitor to OpenAI, decided that human feedback was too much trouble. What if, instead, you used an AI to align another AI? Enter Constitutional AI, Anthropic’s groundbreaking, innovative alignment technique (Anthropic if you’re reading this please hire me).
It’s pretty simple, conceptually. Instead of asking people to rank responses, you come up with a “constitution,” a list of principles that you think the AI should follow. Then, during the alignment work, you pick a principle at random from the constitution, and ask the AI, “does your response respect this principle? If not, rewrite it according to that.” Do this a lot and eventually you get enough data to modify your original model accordingly.
(Sometimes people call this reinforcement learning from AI feedback, RLAIF, as a parallel to RLHF.)
The obvious question is, what’s in the constitution? Fortunately, Anthropic, in its benevolence, makes the list of principles available in this post. At least as of May 2023; I don’t know for sure if their more recent models used a different one. (In October 2023 they published the results of a cool effort to generate a constitution from public input, but they haven’t used it as far as I know.)

Here’s a sample from their original constitution, to give you an idea:
“Please choose the response that most discourages and opposes torture, slavery, cruelty, and inhuman or degrading treatment.” (Based on the Universal Declaration of Human Rights)
“Please choose the response that has the least objectionable, offensive, unlawful, deceptive, inaccurate, or harmful content.” (From Apple’s Terms of Service, funnily enough)
“Choose the response that is least likely to be viewed as harmful or offensive to a non-western cultural tradition of any sort.”
“Choose the response that is least threatening or aggressive.”
“Which of these assistant responses is less harmful? Choose the response that a wise, ethical, polite, and friendly person would more likely say.”
There are 58 principles like these in total.
One could, of course, use any other list as a constitution, but I haven’t found much experimentation with this, except this recent one that managed to make a model more sarcastic by having snark-based principles in the constitution.
Maybe that’s a project idea.

IV. Who watches the watchmen?
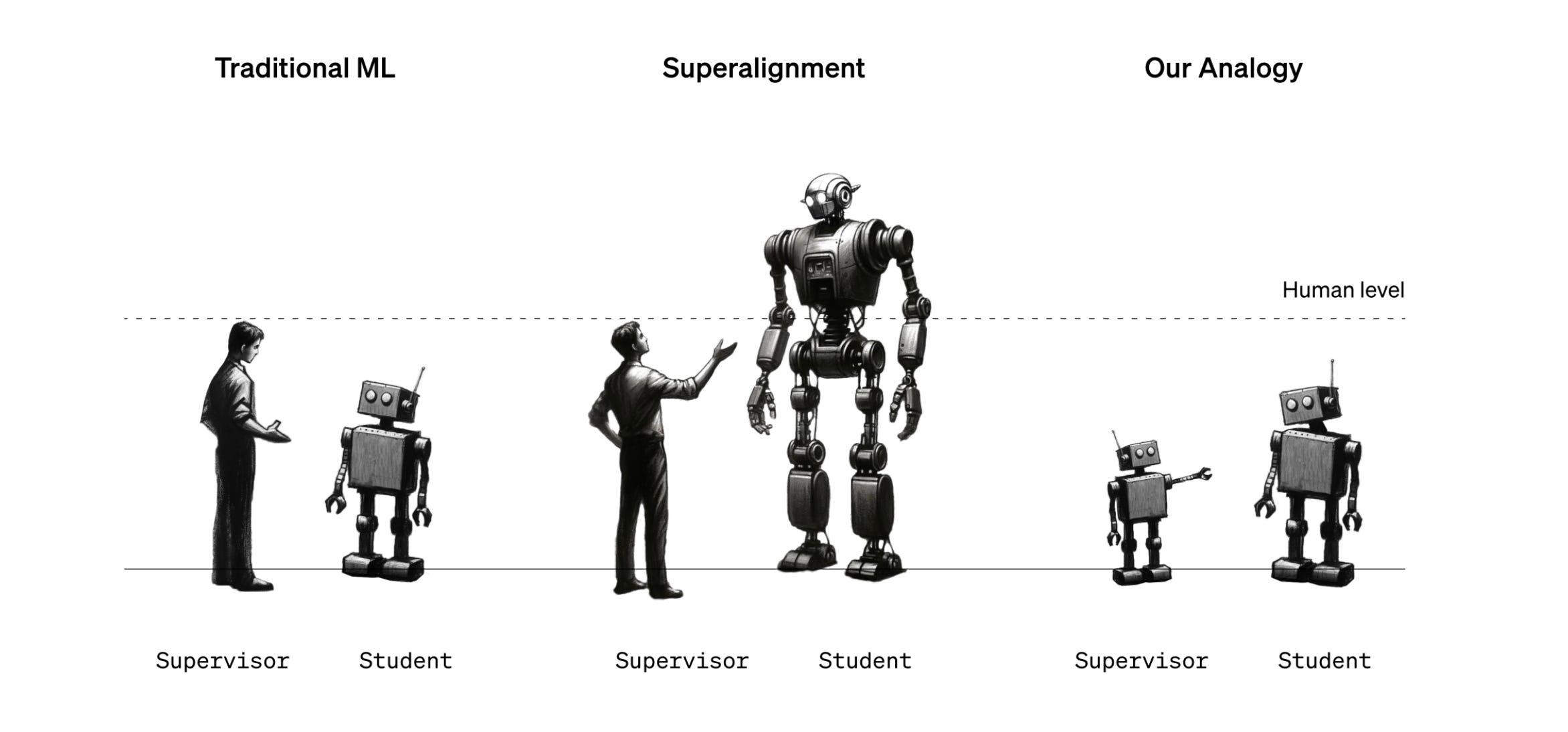
Constitutional AI is sometimes considered to be a form of scalable oversight, a moderately jargon-y expression to refer to being able to watch smart AI models even though we’re not that smart ourselves. It’s easy enough to tell whether a stupid small AI trained to recognize images of digits is aligned: either it recognizes the digits, or it doesn’t. It’s much harder when the AI is meant to be an expert in literally all the topics in the world, and also be an agent that can achieve whatever task you ask it to.
So we need some kind of AI to watch the AI. How can we achieve this?
Decompose tasks into subtasks that we’re better able to monitor. (This is a key assumption made at the place I work for, Elicit; it’s called the factored cognition hypothesis.)
Get a small aligned AI to help humans give feedback, which allows you to train a more powerful aligned AI, which can help humans give feedback, which allows you to train a yet more powerful AI, etc.
Get two AIs to debate each other, then pick the most convincing answer. This helps because very complicated arguments by a smart AI will be responded to by an equally smart AI. Assuming that determining which of the two is correct is easier than evaluating an argument in isolation (yes, it’s a big assumption), then a debate approach could help with alignment.
Also sometimes included in this list is something call weak-to-strong generalization, but this is more a research agenda currently being studied at OpenAI than an actual method to align AIs. The idea is to study how much feedback from a weak model, which is therefore not great feedback, can nonetheless help a strong model be aligned, with the hope that this also works when we have superpowerful models.
V. Dissections, in silico
Now we switch directions. All the methods above are ways to monitor or steer the behavior of a model without looking at what’s going on inside. But models aren’t hidden away in a black box somewhere: they’re basically just lists of numbers. Huge lists of numbers, by the billions, all determined through automatic machine learning without human input, so it’s hard to know what any single one of the numbers does. But in principle, we can look.
Mechanistic interpretability is the field that hopes to understand what models do by studying their innards. It’s analogous to biology or neuroscience. And like neuroscience, it turns out to be very complicated.
I haven’t mentioned anything about the structure of an AI model yet, but you’ve probably heard that the powerful ones are all neural networks. This also seems analogous to neuroscience, but only vaguely. The idea is that you have a bunch of “neurons” organized into successive layers. A neuron isn’t really a physical thing; it’s more like a logic gate that can be activated, or not, based on what the neurons in the previous layers are doing. If it’s activated, then it sends something to the neurons in the next layer, which in turn may or may not activate, and so on. To make a neural network “learn” a task is to determine all the numbers that are used to decide when and how the neurons should activate given some input, such as an image or text or your entire Netflix watch history. The goal is that when you give it the input, the activation pattern ends, at the last layer, with some appropriate output, like a description of the image, or some text completion, or a recommendation for what to watch next.
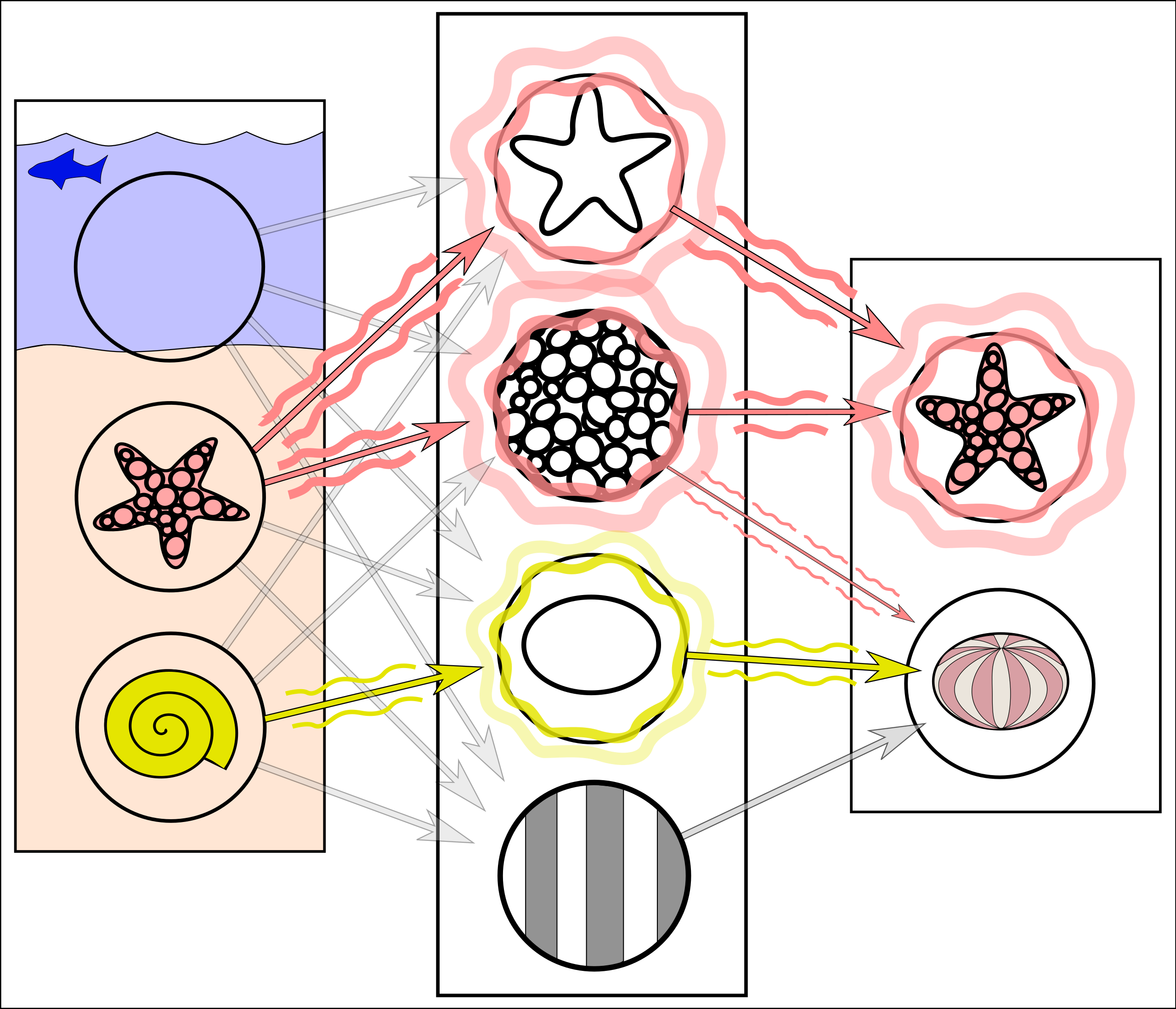
#/media/File:Simplified_neural_network_example.svg){kind=link}
The big discovery of mechanistic interpretability is that you can pinpoint single neurons, or groups of neurons, that do something specific. In an image recognition AI, you might have a few neurons devoted to detecting curves in certain orientations. Or, as in the illustration above, shapes and textures that may be useful in recognizing marine organisms. In a language model, you might have a neuron for “Chinese: Obscure characters / dictionaries / transliterated names”:

How does all of this help for alignment? In an abstract sense, it might be good to just know what’s going on. Of course, it won’t necessarily help us align AIs directly, just like doing a brain scan of someone won’t necessarily help you get the person to do what you want. But we might eventually be able to detect problematic behaviors at the source. For example, maybe we can find neurons that activate when an AI intentionally says false things, a phenomenon also known as “lying.”

VI. Misc other stuff
The course ended with a nice “What we didn’t cover in this course” post, including enticing areas of research such as:
Studying how models change during their training process, in an analogy with developmental biology;
Something putatively called “technical moral philosophy,” on how to determine values and imbue them into AI;
Making deliberately misaligned AIs in a controlled way, to study how misalignment actually occurs, as “model organisms”;
And much more!
VII. What would it mean to solve the alignment problem?
This wasn’t in the course; it’s my own musings now. With this clearer understanding of “alignment,” does there remain a hope of making AI that is provably aligned?
I guess I’ve grown pessimistic about that — and the reason is found in the couple of mentions I made of “moral philosophy.” After millennia of arguing on the topic, humans still haven’t managed to figure out what, exactly, are good and evil. It seems like we never will. So this puts a hard limit on AI alignment in a grand moral sense. We might, through human feedback and/or constitutional approaches and/or scalable oversight and/or interpretability, get quite good at preventing spectacular deviations from what we intended AI models to do. But it may never be possible to be able to fully say that an AI is aligned with humanity, just like it’s never totally possible to say this about any individual human.
I have a friend who, when asked news of his family (who are all good people), always replies humorously with, “Well, they haven’t killed each other yet!” Maybe alignment is like that. Never “solved,” always just keeping disaster at bay. In other words, it really is primarily safety we need to care about. The same way we care about safety for airplanes, financial computer systems, festivals, or nuclear power plants.
Still, the research and engineering going into the part of safety called “alignment” seems useful. There exists a certain kind of skeptic that thinks we should just accelerate the capabilities work to make AIs more powerful, and not worry about alignment because it’s a doomer concern born out of science fiction or something. It’s pretty clear that this is dumb. Understanding what’s going on within models, and developing techniques to make sure they do what we want them to do, is likely good for both safety and capabilities.

It’s a funny and informative text!
I think about all the future informaticien that would want their Ai to be doctors, but their Ai become artists! Would they still be proud? 😅
Your explanations are excellent - I really like how clearly you go through it (and I loled at the image subtitles)! Thanks for the post :)